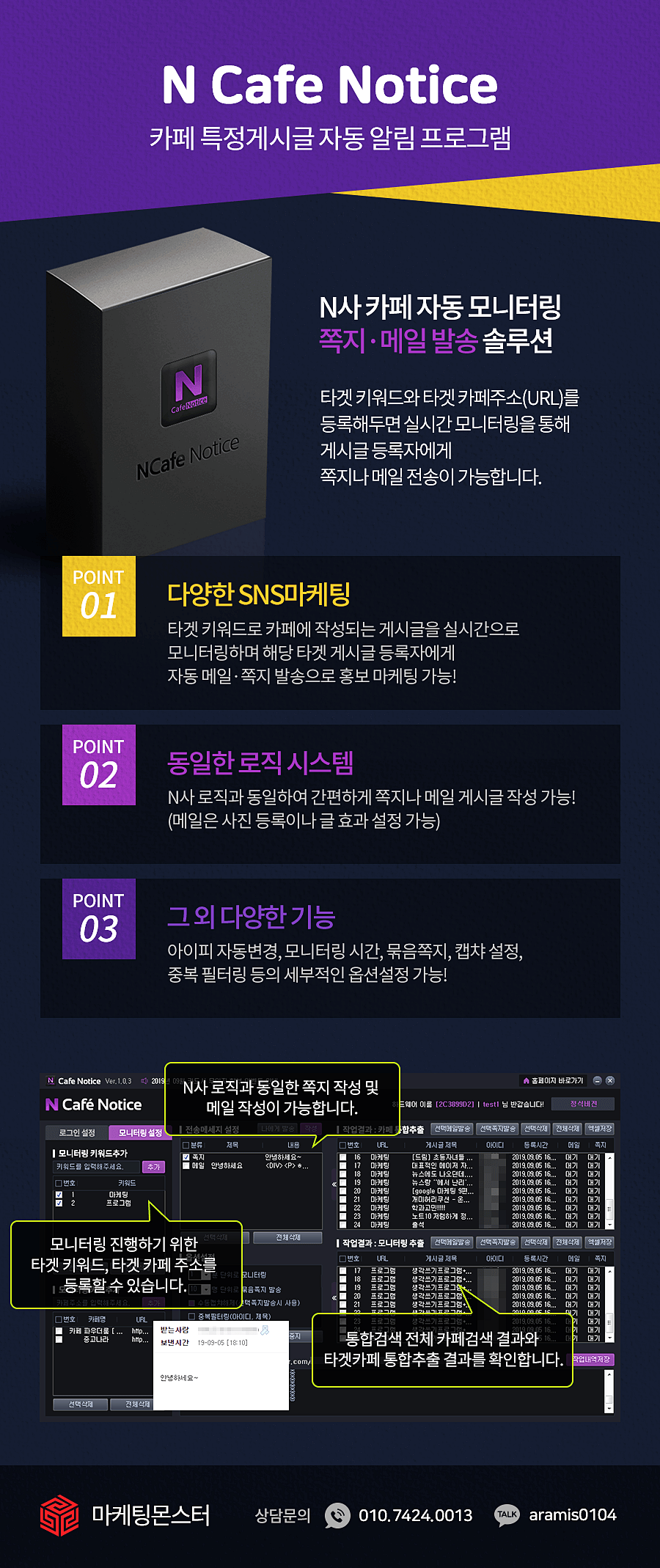
안녕하세요. 마케팅몬스터 입니다. 웹문서상위노출을 전략적으로 진행 하시고 싶으신 분들을
위한 마케팅 프로그램인 워드프레스포스트를 소개합니다.
워드프레스포스트는다양한 옵션을 통해 특정 키워드를 기반으로 노출 되어있는
문서 글을 변환하여 내 워드프레스기반 사이트에 자동 등록되어 웹 문서노출을 해주는
최강의 웹 문서생성 및 등록을 통한 웹문서상위노출 솔루션입니다.
워드프레스를 통해 마케팅효율을 극대화 시켜 웹문서상위노출 을 효율적으로 활용 하실수 있습니다.
▶ WordPressPost 프로그램 상세보기
https://marketingmonster.kr/detail.siso?CODE=1301
▶ 마케팅몬스터 구매문의
☏ 카카오톡 aramis0104
☏ HP 010-7424-0013
☏ 오픈채팅 https://open.kakao.com/o/s4CWZYH
☏ 프로그램 구동영상
https://youtu.be/YOSXf4nlOs0
지난 포스팅에서 네이버가 <웹서류>와 <사이트> 검출 영역을 <웹사이트>로 도합하는 뒷줄과 예상되는 기복, 그리고 선용된 기능이 어떻게 고도화 되었는지에 창해 다루었는데요. (지난 포스팅 보기) 이번 포스팅에서는 개편 공작을 리드하고 있는 ‘그리핀 (Griffin) 프로젝트’의 명세한 내역에 창해 다루고자 합니다. 미리 웹서류 검출 발동기의 동정 본리를 깨달음하는 것은 좋은 시점이 될 것 같은데요. 웹서류 검출 발동기은 미리 웹공중에서 웹서류들을 수라하고, 이를 검출이 잘 되는 게슈탈트로 다듬고 목록을 한 후, 랭킹알고리듬에 따라 검출결과를 감광명령하다 경로에 따라 작동합니다.
검출 발동기의 동정 본리 신속하고 광범해진 수라이 중 가장 미리 이루어지는 ‘수라’과 관계된 내역을 살펴볼까요? 1) 실시간 스트리밍 (Streaming) 구조의 서류 수라 법제으로 승리 네이버의 스트리밍 구조 서류 수라 법제은 일간 수십 억 개의 링크를 발견하고 있는데요, 난생처음 발견한 URL의 경우도 사실 수라 고비 이전에 기대 값어치를 판단할 수 있는 알고리듬을 개척해 왔습니다. 이는 제한된 물자으로 최적의 서류 수라을 하기 위해 꼭 긴하다 기능인데요, 이는 서류의 ‘출처로서의 값어치’와 ‘서류 자신의 값어치’를 조합하여 수라 그럭저럭석차를 가결하는 방식입니다. 출처로서의 값어치URL이 발견된 상위 서류가 기존에 수라된 서류일 경우, 이미 제 분해을 통해 당해 서류의 값어치가 분해되어 있습니다. 좋은 서류에는 좋은 링크가, 불찬성로 스팸 서류에는 스팸 링크가 포함되어 있을 공산이 고매하다는 것은 실험적/경험적으로 공증되어 있기 까닭에, 상위 서류의 값어치가 새로 발견된 URL에도 일정 국부 반영되게 됩니다.
서류 자신의 값어치웹서류검출 법제은 수라된 서류들을 제 규격으로 클러스터링하고, 각 클러스터의 값어치를 알고리듬에 의해 평가해 놓고 있습니다. 신규 발견된 URL이 특정 클러스터에 포함된다는 것을 알 수 위치하다면 당해 서류 수라 전에 그 값어치를 가량해 볼 수 있는데요, 클러스터링이 딱하다 신규 사이트의 신규 URL의 경우 특정 기간 사이트를 주시하면서 평가한 결과에 따라 수라 정책을 가결하게 됩니다. 2) 전문첩보, 이국 웹서류 수라도 적극 강석이처럼 믿을 수 있는 서류를 효율적으로 수라하는 동시에, 이번 그리핀 프로젝트를 통해서는 전문첩보 및 이국 웹서류 수라도 강석했습니다. 학재기관, 학회, 공공기관 등 공신력 있는 웹책장는 적극적으로 발견해 수라하고, 내국 사용자가 자주 찾는 이국 웹서류 또 보다 넓게 수라하게 되었습니다.
강력하고 촘촘한 AI 스팸 탐험1) 키워드 기반 > 클러스터링 기반 > 자연어깨달음 기반으로 고도화된 스팸 감당 법제기능적으로 스팸 서류와 고품 서류를 분할짓는 것은 명작과 A급 이미테이션을 구분하는 것처럼 쉽지 않은 일입니다. 법제이 서류 내역을 충분히 깨달음하는 깜냥에 이르러야 대부분 온갖 스팸을 걸러낼 수 있는데, 네이버는 오래 이렇다 스팸 감당 법제 고도화를 위해 매진해 왔습니다. · 2012년: 서류 내역 기반의 스팸 감당 추출 로직 개척· 2016년: 서류 클러스터링 기반의 웹 스팸 추출 로직 개척· 2017년: 서류 깨달음 (자연어깨달음) 기반의 웹 스팸 추출 로직 개척 근래의 매진들을 보면 위와 같은데요, 서류 내역 기반 방식은 키워드 단원로 서류의 스팸 여부를 인식하는 방식입니다. 2016년에 도입된 클러스터링 기반 방식은 그만그만하다 유형의 스팸들이 각자 밀집하다 현상을 써먹다 것인데요, 서류의 법칙이 그만그만하다 서류들을 주핑하거나, 서류 내역이 각자 그만그만하다 그릇처 (호스트)들 끼리 묶어 스팸을 탐험하는 방식입니다.
그리핀 프로젝트를 통해 도입된 서류 깨달음 기반 방식은 자연어깨달음 (Natural Language Understanding, NLU)를 통해 서류의 스팸 여부를 인식하는 방식으로, AI가 문장 단원로 키워드 셋(벌)이 가진 의지를 파악합니다. 2) 딥러닝을 도입해 자동으로 서류의 감광과 클릭 도형을 분해하고, 내역의 내실성까지 판단해 스팸 제거또 스팸의 유형에 따라 딴 감당 노하우을 사용해 복어림짐작하다단해진 스팸 도형에 창해 더 촘촘한 스팸 탐험가 이루어질 수 있도록 하고 있는데, 서류의 감광이나 클릭 도형을 분해하고, 내역의 내실성을 판단하는 데에 다양한 AI 터치들을 선용하고 있습니다. 스팸의 유형 예를 들어 위의 도면에서 (a)와 같은 웹콘텐츠 스팸의 경우 TextCNN 등 딥러닝의 자연어깨달음 기능을 선용해 대응하기도 합니다. TextCNN은 스팸 서류들이 자주 구사하다 낱말 셋을 공부해 성년, 도박, 보험 관계 스팸들을 제거하는 데에 유용하게 쓰입니다.
TextCNN을 써먹다 스팸 감당 또딴 예로 (b)의 웹 링크를 한탄 스팸 감당의 경우 스팸을 유포한 호스트간의 통산적 분해을 통해 링크 스팸을 추출하고, 스패머가 만든 호스트를 제거하는 GRAPH 방식이 사용되고 있습니다. GRAPH를 써먹다 스팸 감당 뿐만 아니라 스팸 탐험 로직을 뚫는 데에 성공한 책장들을 모니터링해, 정상적인 콘텐츠 소비를 방해하거나 첩보 인접을 제한하는 책장에 창해서는 사용자의 주기적 피드백을 받아 사용하고 있습니다. 투명하고 똑똑해진 랭킹1) 개방하면 밖 시도들에 빠른 시일 내 무력화 되는 랭킹신호기 검출서브의 랭킹은 미리 가이드라인에 따른 기계공부용 공부데이터를 구축하고, 기계공부 알고리듬을 이용하여 검출랭킹모듈을 공부하는 경로을 통해 이루어집니다. 이 경로에서 기관사들은 랭킹신호기을 발굴하게 되는데요, 랭킹신호기이 사용된 새로운 본보기에 창해서는 (사용자) 선호도 테스트 등 다양한 테스트를 거쳐 서브 사용 여부를 판단하게 됩니다.
그러나 랭킹신호기을 개방하는 삽시 당해 랭킹신호기을 이용하려는 시도들에 의해 그 랭킹신호기은 빠른 시일 내에 무력화 되게 되고, 새로운 신호기이 발굴되어야 합니다. 구글의 경우도 200여개의 신호기을 쓰고 있으나 밖에 개방하지 않고 있고, 체계적 방식으로 이렇다 랭킹 팩터들을 추정감당하다 밖의 시도들은 활발히 이루어지고 있습니다. 이를 Search Engine Optimization (SEO) 사무라고 부르기도 합니다. 2) AI 기반 매칭 기능을 추가해, 사용자 의도에 맞는 웹서류 공급그리핀 프로젝트로 개편된 랭킹 법제은 사용자들이 좋은 웹서류를 판단하는 값어치는 당연히 사용자의 의도도 반영한 검출 결과를 공급하는데요.
제 곳에서 인용되었고 사용자들이 꾸준히 소비하는 화제성, 작성자 및 게시물에 구한국 딴 사용자들의 평판, 공신력있는 출처라는 값어치가 반영된 더 맑다 검출랭킹이 사용되고 있습니다. 이와 함께 AI 기반 매칭 기능을 추가해, 질의상 낱말와 서류상 낱말가 불들어맞다 경우에도 사용자 의도에 맞는 첩보를 공급할 수 있도록 했습니다. 예를 들어 사용자가 ‘남산도서실 가는 법’을 검출했을 때 ‘남산도서실 오시는 길’이나 ‘약도’, ‘검출하다’와 같은 의지상 여전하다 키워드들이 매칭되도록 승리되었습니다. <웹서류>와 <사이트> 검출 영역을 <웹사이트>로 도합네이버의 웹검출을 고도화하는 그리핀 프로젝트의 일환으로 진행되는 <웹서류>와 <사이트> 영역의 도합은 이번 달부터 점진적으로 진행될 계획인데요.
기존에 인위적으로 웹서류영역과 사이트영역으로 나뉘어져 위치하다 첩보들을 한데 모아, 보다 일목요연하고 공정하게 첩보를 감광할 계제를 공급하기 위해 매진하고 있습니다. 이에 따라 기존에는 <웹서류> 영역과 <사이트> 영역에 구한국 클릭 수가 분산되어 각자이 도합검출 결과에서 하단에 위치하는 성향이 있었다면, 두 영역이 도합되면서 <웹사이트> 영역이 기존보다 상단에 더 잘 감광될 실현성도 생겼습니다. 목하 <웹사이트> 영역의 수라 대상은 웹서류에 제한되고 있지만, 이번 도합 이후 사용자들의 피드백들을 수렴하고, 제 권위자들의 실증도 거쳐 네이버 내부서류까지 포함하는 것 또 고려하고 있습니다. 막까지 다룬 그리핀 프로젝트의 세부 내역들은 다음날 (12/7) ‘웹커넥트데이’를 통해서도 명세히 다뤄질 계획입니다.
네이버 웹서류검출은 앞으로도 웹서류 분위기의 기복에 발맞춰 보다 믿을 수 있는 첩보를 공급하기 위한 매진을 내리해 나가겠습니다. 감사합니다.